
 ���T��Ʒ���I
���T��Ʒ���I���һ�����nj��F���N����
�Z������
�����҂�Ҫ���F�����Z������.���D��ʾ:
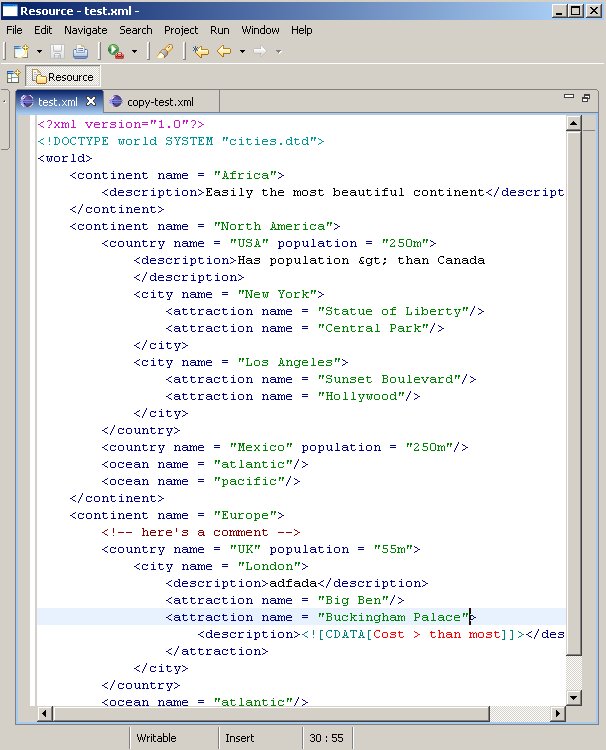
�ı��|�ρ��f,�Z���������ǽo�ָ���Tokenָ���������@ʾ����,���Z��������̎��C������Ҳ��Ҫ�õ�Token, Scanner��Rule�@Щ�|��.ͨ�^�͌�SourceViewerConfiguration��getPresentationReconciler()�������oָ���ă�����������Z������������:
- public IPresentationReconciler getPresentationReconciler(ISourceViewer sourceViewer)
- {
- PresentationReconciler reconciler = new PresentationReconciler();
- DefaultDamagerRepairer dr = new DefaultDamagerRepairer(getXMLTagScanner());
- reconciler.setDamager(dr, XMLPartitionScanner.XML_TAG);
- reconciler.setRepairer(dr, XMLPartitionScanner.XML_TAG);
- dr = new DefaultDamagerRepairer(getXMLScanner());
- reconciler.setDamager(dr, IDocument.DEFAULT_CONTENT_TYPE);
- reconciler.setRepairer(dr, IDocument.DEFAULT_CONTENT_TYPE);
- ...
- return reconciler;
- }
������Ĵ��a����һ��IPresentationReconciler����,�����Á��O �ӵ�IDocument������׃��,һ��������͕���һ��IPresentationDamager��IPresentationRepairer�������P,�����ęn�r,�����o��Ӱ푵��ęn�^��������͵�IPresentationDamager�����l����Ϣ,����IPresentationDamager������һ��IRegion����,�����@Щ��Ϣ���f�oIPresentationRepairer����,ԓ���������l����׃�ą^�������O���@ʾ����.
�����^�� �������ܱ��^���s,���^�f�ҵ����҂�������Ҫ�Լ�ȥ���F�@Щ�|��, JFace�ṩ��һ��DefaultDamagerRepairer��̎��IPresentationDamager��IPresentationRepairerҪ��������,ͬ�r߀�ṩ��һ��PresentationReconciler��Á팢�����P����,���҂�Ҫ���ľ��Ǹ��V������ʹ�ýo���ă�����͌��ęn�M�зָ�֮��ĽY�������ӵ�,�Լ�ÿһ�N�ęn��͵��@ʾ����
DefaultDamagerRepairer�Ę�������Ҫһ��ITokenScanner ����,ԓ�ӿڸ��ָ�Token Scanner�dz����,�ɷNScanner�õ���Token����IToken��һ�N���F,��֮ͬ̎����Token���Ȳ�ͬ,�ָ�Token Scanner�õ���Token��һ������ij�N������͵��ęn�^��,��ʹ���Z������Scanner�õ���Token��һ�ξ�����ͬ�ı���ʽ���ַ�������,�@Ȼ���ߵ����ȸ���
�@���҂���XMLTagScanner���f,ԓScanner��Ҫᘌ�XML_TAG�������, ������õ���Token��ʾ����λ��XML���R��֮�g���ı�����
- public class XMLTagScanner extends RuleBasedScanner
- {
- public XMLTagScanner(ColorManager manager)
- {
- Color color = manager.getColor(IXMLColorConstants.STRING);
- TextAttribute textAttribute = new TextAttribute(color);
- IToken string = new Token(textAttribute);
- IRule[] rules = new IRule[3];
- // Add rule for double quotes
- rules[0] = new SingleLineRule("\"", "\"", string, '\\');
- // Add a rule for single quotes
- rules[1] = new SingleLineRule("'", "'", string, '\\');
- // Add generic whitespace rule.
- rules[2] = new WhitespaceRule(new XMLWhitespaceDetector());
- setRules(rules);
- }
- }
XMLTagScanner�^����RuleBasedScanner,��˺��҂���RuleBasedPartitionScanner�п�����һ��,��Ҳ��ʹ��ij�NҎ�t̎��C�Ɓ��R�eToken��
�@���҂����x������Ҏ�t:һ������ƥ���p��̖�е��ַ�,һ������ƥ�����̖�е��ַ�,߀��һ���t�Á�ƥ��ո�
���˽oXML�Ę˺����@ʾ���{ɫ,�҂�ʹ�����µĴ��a,���oToken�O��һ��Ĭ�J���ɫֵ:
- protected XMLTagScanner getXMLTagScanner()
- {
- if (tagScanner == null)
- {
- tagScanner = new XMLTagScanner(colorManager);
- Color color = colorManager.getColor(IXMLColorConstants.TAG);
- TextAttribute textAttribute = new TextAttribute(color);
- Token token = new Token(textAttribute);
- tagScanner.setDefaultReturnToken(token);
- }
- return tagScanner;
- }
���ݸ�ʽ��
��ʽ������ͨ�^ʹ�ÿs�M�Ϳո�ʹ�ęn�Y����,�Ķ������п��x��, ��ʽ��̎�������ɂ����E:
��һ��,�鼴����ʽ���ă��ݶ��x��ʽ������,�@Щ���Կ�����ȫ���Ե�,Ҳ������ᘌ�ij���ָ�^���.ͨ�^IFormattingStrategy�ӿځ팍�F.
�ڶ���,ͨ�^SourceViewerConfiguration���FoISourceViewer�����@Щ����
��ʽ��Ҳ��ʹ�õ��ָ�̎��,�@�҂���һ���w�����������Լ����_ʹ���ęn�ָ����Ҫ��.�����҂�������ε�TextFormattingStrategy���M���f��,ԓ��ʽ����������̎��Ƕ����XMLԪ���е��ı�����
- public class TextFormattingStrategy extends DefaultFormattingStrategy
- {
- private static final String lineSeparator = System.getProperty("line.separator");
- public String format(String content,
- boolean isLineStart,
- String indentation,
- int[] positions)
- {
- if (indentation.length() == 0)
- return content;
- return lineSeparator + content.trim() + lineSeparator + indentation;
- }
- }
�@���҂�ͨ�^�^��DefaultFormattingStrategy���͌�format�����팍�F, ����w�����nj��ı������M��trim̎��,Ȼ�����ı�ǰ����ϓQ�з�
����Ľ�B����̫����,���҂��Č��F�XMLFormattingStrategy�а����˸����s�ĸ�ʽ��̎�����a,�@���҂����会������һһչ�_,���dȤ���x�߿����Լ�ȥ�����w��,�����f��ʽ��̎����һ헷dz��������ԵĻ,�����߀�漰�����x����ı��M�������R�e��̎��,�@����Ҫ���͵Č����ܵõ�����ĽY��
ͨ�^���dSourceViewerConfiguration.getContentFormatter()�������Էdz����Č���ʽ���������ӵ�������
- public IContentFormatter getContentFormatter(ISourceViewer sourceViewer)
- {
- ContentFormatter formatter = new ContentFormatter();
- XMLFormattingStrategy formattingStrategy = new XMLFormattingStrategy();
- DefaultFormattingStrategy defaultStrategy = new DefaultFormattingStrategy();
- TextFormattingStrategy textStrategy = new TextFormattingStrategy();
- DocTypeFormattingStrategy doctypeStrategy = new DocTypeFormattingStrategy();
- PIFormattingStrategy piStrategy = new PIFormattingStrategy();
- formatter.setFormattingStrategy(defaultStrategy, IDocument.DEFAULT_CONTENT_TYPE);
- formatter.setFormattingStrategy(textStrategy, XMLPartitionScanner.XML_TEXT);
- formatter.setFormattingStrategy(doctypeStrategy, XMLPartitionScanner.XML_DOCTYPE);
- formatter.setFormattingStrategy(piStrategy, XMLPartitionScanner.XML_PI);
- formatter.setFormattingStrategy(textStrategy, XMLPartitionScanner.XML_CDATA);
- formatter.setFormattingStrategy(formattingStrategy, XMLPartitionScanner.XML_START_TAG);
- formatter.setFormattingStrategy(formattingStrategy, XMLPartitionScanner.XML_END_TAG);
- return formatter;
- }
�������a���x������һ��formatter,Ȼ��ͨ�^formatter��setFormattingStrategy()�����o�҂���ÿһ���������ָ��һ������ʽ�����Լ���.
�������A��X�WУ���I�IҎ���������ṩ�����������ھ���ԃ��


